基于ELK日志分析demo¶
Table of Contents:
背景介绍¶
大数据时代,随着数据量指数性增加,存储与计算集群的规模也逐渐壮大,几百上千台的云计算环境已不鲜见。现在的集群所需要解决的问题不仅仅是高性能、高可靠性、高可扩展性,还需要面对易维护性以及数据平台内部的数据共享性等诸多挑战。系统运维数据既能实现数据平台各组件的集中式管理,方便系统运维人员,提升运维效率,又能反馈系统运行状态给系统开发人员。例如分析数据仓库的日志可以按照时间序列查看各数据库实例各种级别的日志数量与占比,分析应用服务器的日志可以查看出错最多的模块、下载最多的文件、使用最多的功能等;大数据时代的业务与运维将紧密地结合在一起。
几种常见日志系统介绍¶
所有信息系统平台每天会产生大量的日志,这些日志主要包括系统日志、应用程序日志和安全日志,日志通常以流式数据为主,包括用户访问记录、数据库操作记录等。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。当数据量达到一定的数量级,传统的单节点系统已经无法完成检索及分析任务,必须使用分布式的日志系统对他们进行处理。一般而言,这些系统需要具有以下特征:
收集-能够采集多种来源的日志数据
传输-能够稳定的把日志数据传输到中央系统
存储-如何存储日志数据
分析-可以支持 UI 分析
警告-能够提供错误报告,监控机制
flume¶
flume是分布式的日志收集系统,它将各个服务器中的数据收集起来并送到指定的地方去如图中的HDFS
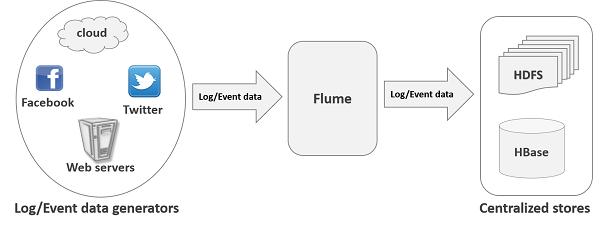
flume的核心就是一个agent,这个agent对外有两个进行交互的地方,一个是接受数据的输入:source,一个是数据的输出sink,sink负责将数据发送到外部指定的目的地。agent本身是一个java进程,运行在日志收集节点—所谓日志收集节点就是服务器节点。 个agent对外有两个进行交互的地方,一个是接受数据的输入——source,一个是数据的输出sink,sink负责将数据发送到外部指定的目的地。source接收到数据之后,将数据发送给channel,chanel作为一个数据缓冲区会临时存放这些数据,随后sink会将channel中的数据发送到指定的地方—-例如HDFS等
flume的几个主要特点:
可靠性:当节点出现故障时,日志能够被传送到其他节点上而不会丢失
可扩展性:Flume采用了三层架构,分别为agent,collector和storage,每一层均可以水平扩展
可管理性:所有agent和colletor由master统一管理,这使得系统便于维护
配置繁琐:需要分别作source、channel、sink的手工配置,涉及到复杂的数据采集环境可能还要做多个配置
kafka¶
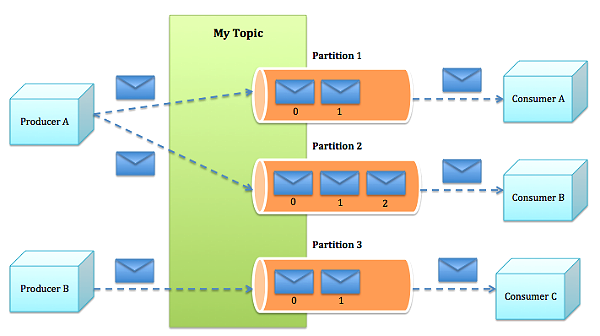
Kafka是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。Kafka 采用 scala 语言编写,使用了多种效率优化机制,采用比较新颖的 push/pull 架构,更适合异构集群,底层采用 Hadoop作为数据平台。它实际上是一个包含 producer,broker和consumer 三种角色的系统。其中 producer 负责向某个topic发布消息,而consumer作为接收方订阅这个 topic 的消息,一旦出现关于这个 topic 的新消息, broker 负责将新消息传递给订阅它的所有 consumer。由此可以看出,在Kafka 中, topic 是组成消息的关键,而为了便于管理数据和进行负载均衡,每个topic又会分为多个partition。同时,Kafka也使用了zookeeper进行负载均衡。
scribe¶
Scribe是facebook开源的日志收集系统,在facebook内部已经得到大量的应用。它能够从各种日志源上收集日志,存储到一个中央存储系统(可以是NFS,分布式文件系统等)上,以便于进行集中统计分析处理。它为日志的“分布式收集,统一处理”提供了一个可扩展的,高容错的方案。当中央存储系统的网络或者机器出现故障时,scribe会将日志转存到本地或者另一个位置,当中央存储系统恢复后,scribe会将转存的日志重新传输给中央存储系统。
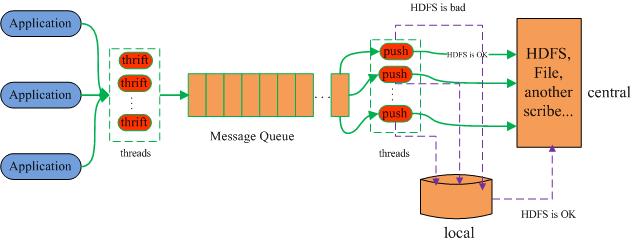
Scribe 的架构较为简单,主要包括三部分,分别为 Scribe Agent、Scribe 和存储系统。Scribe 架构的最大特点是容错性较好,当存储系统发生故障时,Scribe 会将本地磁盘作为存储缓冲区,将数据临时写在本地磁盘上,待存储系统恢复正常后,本地磁盘中的数据会被重新加载到存储系统中。
ELK架构介绍¶
ELK 是elastic公司提供的一套完整的日志收集、展示解决方案。ELK 其实并不是一款软件,而是一整套解决方案,是三个软件产品的首字母缩写,Elasticsearch,Logstash 和 Kibana。这三款软件都是开源软件,通常是配合使用,而且又先后归于 Elastic.co 公司名下,故被简称为 ELK 协议栈。
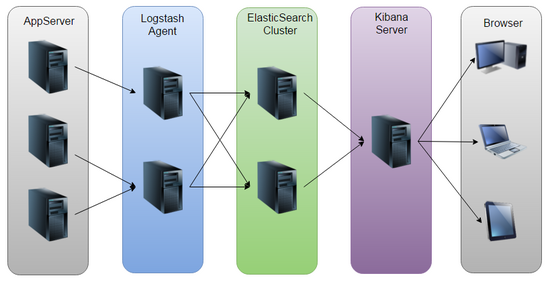
Elasticsearch¶
Elasticsearch 是一个实时的分布式搜索和分析引擎,基于RESTful web接口,它可以用于全文搜索,结构化搜索以及分析。它是一个建立在全文搜索引擎 Apache Lucene 基础上的搜索引擎,使用 Java 语言编写。
Logstash¶
Logstash是一个接收,处理,转发日志的工具。用Elasticsearch作为后台数据的存储,kibana用来前端的报表展示。Logstash在其过程中担任搬运工的角色,它为数据存储,报表查询和日志解析创建了一个功能强大的管道链。Logstash提供了多种多样的 input,filters,codecs和output组件,让使用者轻松实现强大的功能。
Kibana¶
Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。可以用kibana搜索、查看、交互存放在Elasticsearch索引里的数据,使用各种不同的图表、表格、地图等kibana能够很轻易地展示高级数据分析与可视化。
ELK应用实践¶
部署ELK¶
下载软件包
curl -LO https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.5.1.tar.gz
curl -LO https://artifacts.elastic.co/downloads/logstash/logstash-5.5.1.tar.gz
curl -LO https://artifacts.elastic.co/downloads/kibana/kibana-5.5.1-linux-x86_64.tar.gz
tar zxvf elasticsearch-5.5.1.tar.gz
tar zxvf logstash-5.5.1.tar.gz
tar zxvf kibana-5.5.1-linux-x86_64.tar.gz
安装elasticsearch
编辑配置文件``vim /elasticsearch-5.5.1/config/elasticsearch.yml``,修改其中如集群名称``cluster.name``,监听地址``network.host``,监听端口``http.port``等信息,一般elasticsearch单节点配置可以全部用默认。
运行elasticsearch
elasticsearch不允许root用户运,实现创建一个用户:useradd es,修改elasticsearch文件夹
所属组``chown -R es:es /opt/elasticsearch-5.5.1``然后使用es用户执行``su es -c /opt/elasticsearch-5.5.1bin/elasticsearch``
查看运行状态
[root@web-app logstash-5.5.1]# curl -X GET http://localhost:9200/?pretty
{
"name" : "QRyb42R",
"cluster_name" : "web-app",
"cluster_uuid" : "Hq33Or2DSu6CCEgwziNwfQ",
"version" : {
"number" : "5.5.1",
"build_hash" : "19c13d0",
"build_date" : "2017-07-18T20:44:24.823Z",
"build_snapshot" : false,
"lucene_version" : "6.6.0"
},
安装logstash
单节点logstash本身不需要做其他配置,主要是需要编写提供给logstash使用的配置文件,一般配置文件中会指出logstash的输入,输出及过滤方法等信息,如:
input { stdin {} } output { stdout{codec => rubydebug} }
这个配置文件从标准输入获取信息并使用codec编码器,以rubydebug样式输出详细信息,使用``/opt/logstash-5.5.1/bin/logstash -f /opt/logstash-5.5.1/conf/sample.conf``启动logstash并键盘输出字符,显示如下:
[2017-11-23T08:45:33,244][INFO ][logstash.agent] Successfully started Logstash API endpoint {:port=>9600}
hello logstash!
{
"@timestamp" => 2017-11-23T08:53:16.143Z,
"@version" => "1",
"host" => "web-app",
"message" => "hello logstash!"
}
安装kibana
kibana的配置文件放置在kibana安装路径下的config目录中: config/kibana.yml 几个重要的配置项:
port: 5601 kibana WEB使用的端口
host: localhost 指定绑定的主机
elasticsearch_url: http://localhost:9200 指向elasticsearch实例
使用``bin/kibana``来运行kibana实例,浏览器打开http://localhost:5601查看kibana界面
构建一个ELK数据管道¶
分析简单数据集¶
互联网进入网站上可以容易找到股票交易信息,同时这些金融网站也提供丰富的API供查询,以我从google找到的苹果公司(股票代码AAPL)2016-11-14 – 2017-11-14这一年的数据为例:
日期 |
开盘价 |
最高价 |
最低价 |
收盘价 |
加权平均价 |
成交量 |
|---|---|---|---|---|---|---|
2017-11-01 |
169.869995 |
169.940002 |
165.610001 |
166.889999 |
166.292206 |
33637800 |
2017-11-02 |
166.600006 |
168.500000 |
165.279999 |
168.110001 |
167.507828 |
41393400 |
2017-11-03 |
174.000000 |
174.259995 |
171.119995 |
172.500000 |
171.882111 |
59398600 |
2017-11-06 |
172.369995 |
174.990005 |
171.720001 |
174.250000 |
173.625839 |
35026300 |
2017-11-07 |
173.910004 |
175.250000 |
173.600006 |
174.809998 |
174.183823 |
24361500 |
2017-11-08 |
174.660004 |
176.240005 |
174.330002 |
176.240005 |
175.608719 |
24409500 |
2017-11-09 |
175.110001 |
176.100006 |
173.139999 |
175.880005 |
175.250000 |
29482600 |
2017-11-10 |
175.110001 |
175.380005 |
174.270004 |
174.669998 |
174.669998 |
25145500 |
2017-11-13 |
173.500000 |
174.500000 |
173.399994 |
173.970001 |
173.970001 |
16859000 |
2017-11-14 |
173.039993 |
173.479996 |
171.179993 |
171.339996 |
171.339996 |
23756500 |
原始数据中每一行代表了某一天的股票价格,字段用``,``分隔:
2017-11-14,173.039993,173.479996,171.179993,171.339996,171.339996,23756500
配置logstash输入¶
在logstash文件夹conf目录中创建AAPL.conf文件,内容如下:
输入参数部分:
input {
file {
path => "/opt/AAPL.csv"
start_position => "beginning"
tags => "aaple"
types => "stock"
}
}
input类型指定为file,表示从文件读取输入
path指定文件的路径,必填
start_position定义logstash从源文件读取数据的开始位置
tags定义一个字符串可以在之后的过滤流程中针对该tag的事件进行处理
types标记事件的类型,会保存至elasticsearch的文档中并通过kibana的_type字段展示
过滤处理输入数据:
filter {
csv {
columns => {"date","open","close","high","low","close","adj_close","volume"}
separator => ","
}
date {
match => {"date","yyyy-MM-dd"}
timezone => "Asia/Shanghai"
}
mutate {
convert => ["open","float"]
convert => ["high","float"]
convert => ["low","float"]
convert => ["close","float"]
convert => ["adj_close","float"]
convert => ["volume","integer"]
}
}
对CSV文件的处理可以使用logstash中的CSV过滤器``csv{}``,其中:
columns属性指定了CSV文件中的字段名字
separator属性指定csv文件字段用``,``分隔
logstash中提供了date过滤器用了索引日期类型,match属性是一个固定格式的数组,这个格式为字段提供了一组用于该字段的日期格式
mutate过滤器将字段转换为指定的数据类型,包含一些常见数据类型的修改
将数据存入elasticsearch:
output {
elasticsearch {
action => "index"
host => "localhost"
port => "9200"
index_type => "stocks"
index => "apple-stock"
}
}
elasticsearch{} 表示写入数据到elasticsearch插件中
action指定了对输入文件的操作类型,index表示对文档进行索引
host指定elasticsearch的主机名
port指定elasticsearch服务使用的端口
index_type指定了事件写入的索引类型
index指定了索引名称
综上,AAPL.conf完整配置如下:
input {
file {
path => "/opt/AAPL.csv"
start_position => "beginning"
tags => "aaple"
types => "stock"
}
}
filter {
csv {
columns => {"date","open","close","high","low","close","adj_close","volume"}
separator => ","
}
date {
match => {"date","yyyy-MM-dd"}
timezone => "Asia/Shanghai"
}
mutate {
convert => ["open","float"]
convert => ["high","float"]
convert => ["low","float"]
convert => ["close","float"]
convert => ["adj_close","float"]
convert => ["volume","integer"]
}
}
output {
elasticsearch {
action => "index"
host => "localhost"
port => "9200"
index_type => "stocks"
}
}
使用``bin/logstash -f AAPL.conf``运行logstah
使用kibana对数据进行可视化¶
启动kibana:bin/kibana,打开浏览器:http://IP:5601
新建查询为apple-stock*,使用time picker选定事件范围为1年,结果如下
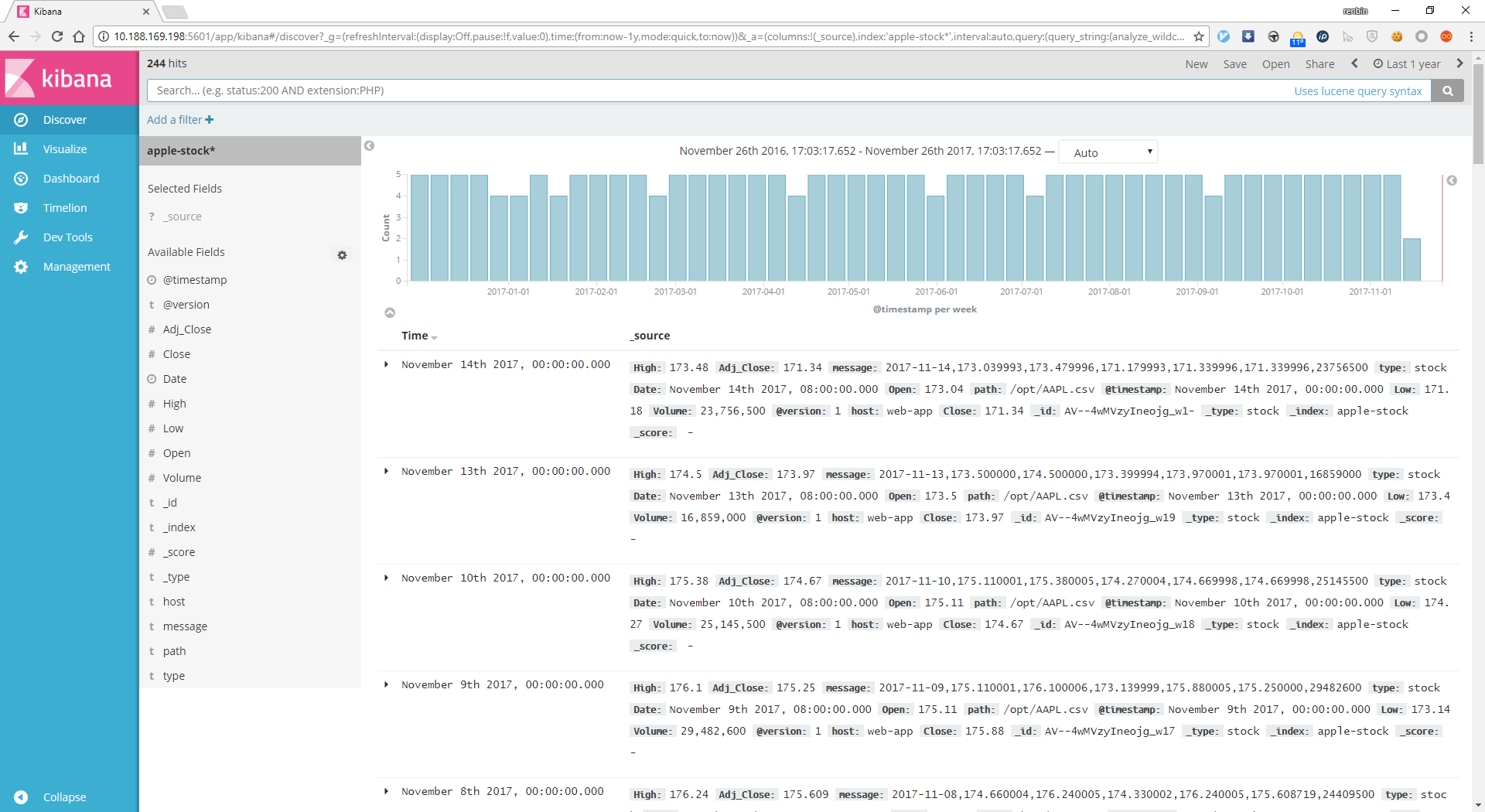
kibana提供丰富的可视化组件,可以创建多种图形:
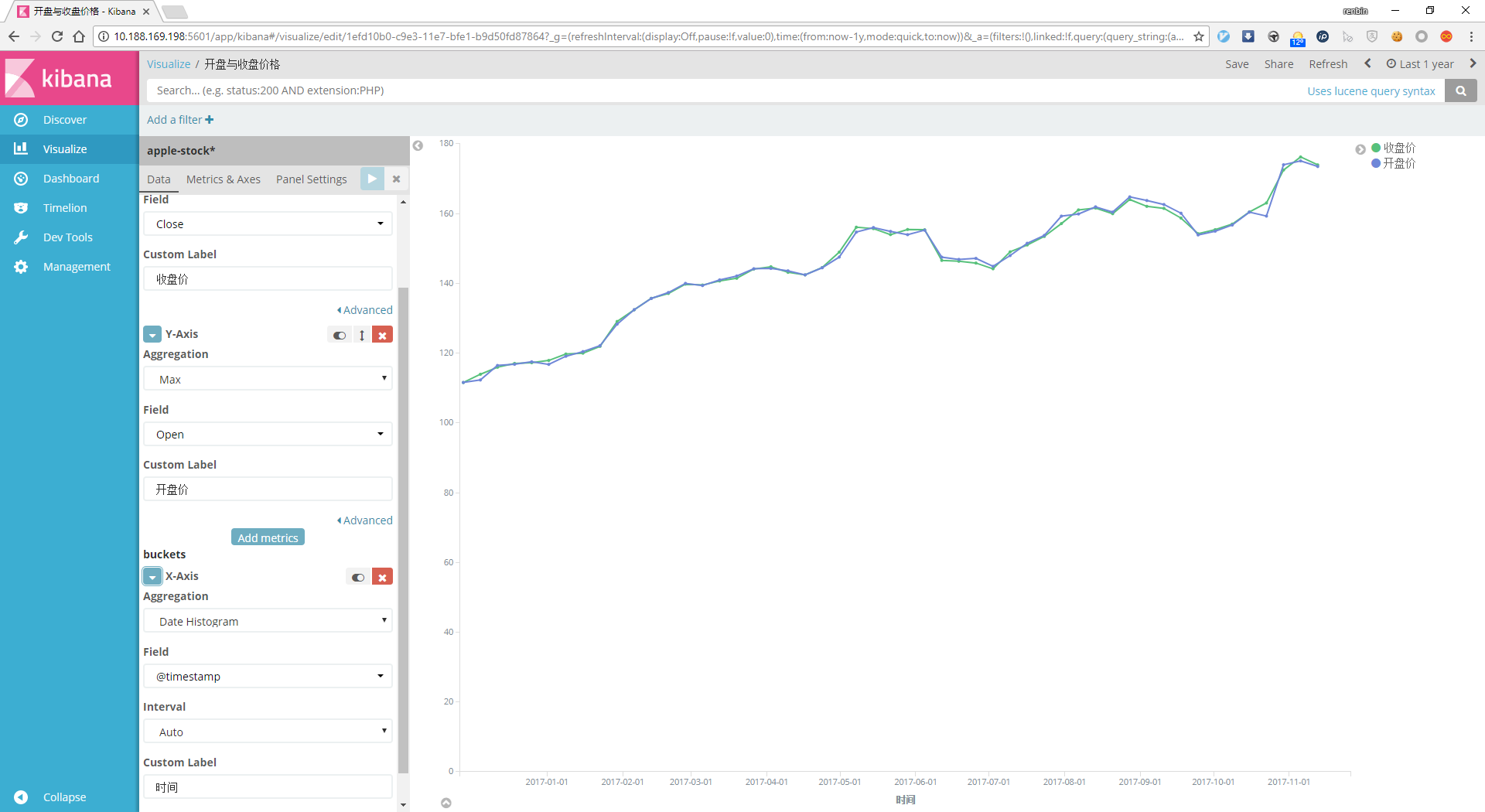
建立折线图¶
在Visualize菜单选择Line折线图,选择创建2条Y-Axix,标签为开盘价与收盘价,Aggregation为Max,字段分别为open与close,X-Axis Aggregation为Date Histogram,根据情况定义时间间隔(Interval),然后保存为开盘与收盘价格:
建立直方图¶
在Visualize菜单选择Vertical Bar直方图,Y-Axix的Aggregation为Sum,字段为交易量Volume,X-Axis Aggregation为Date Histogram,根据情况定义时间间隔(Interval),然后保存为每周交易量:
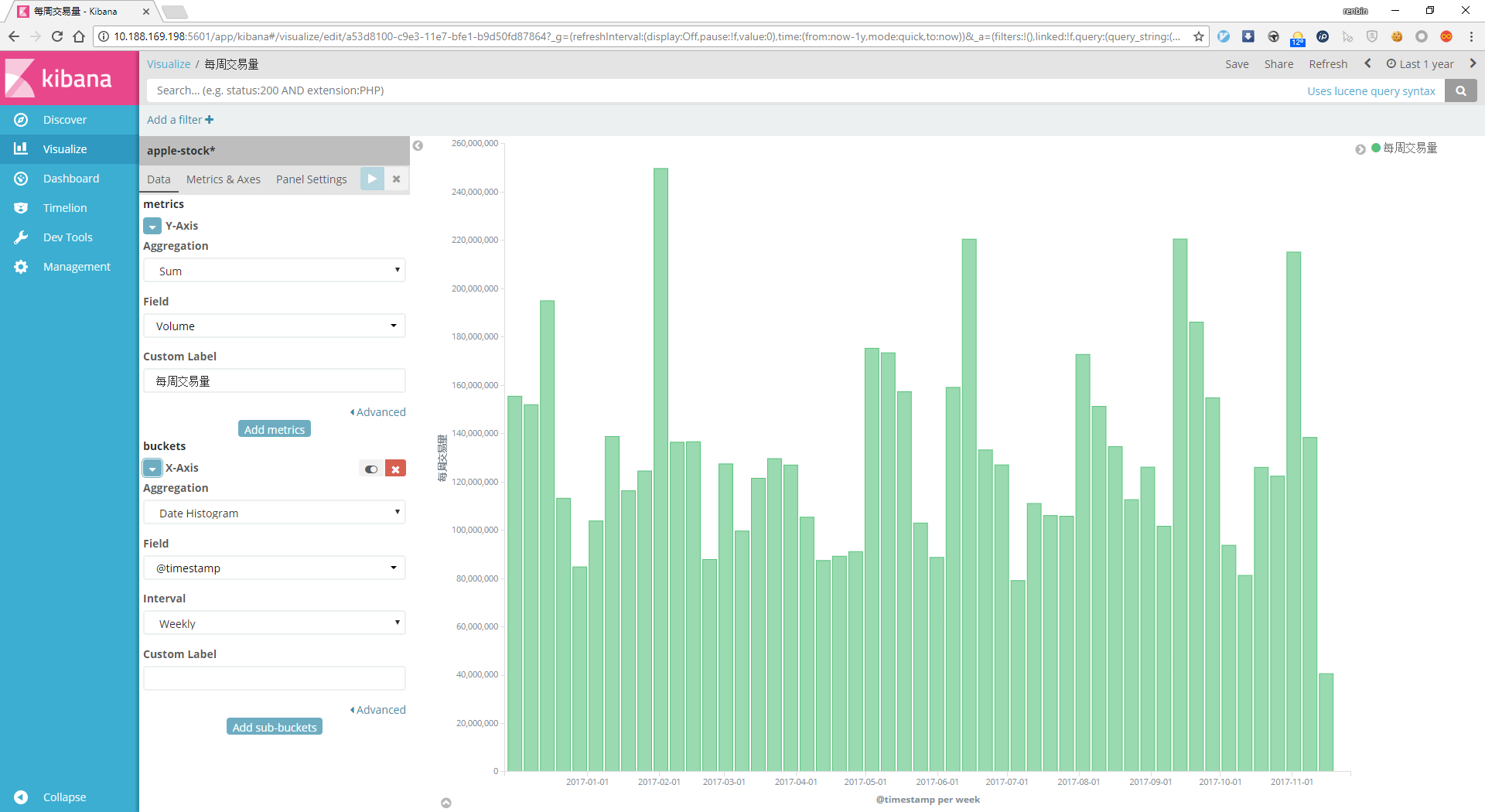
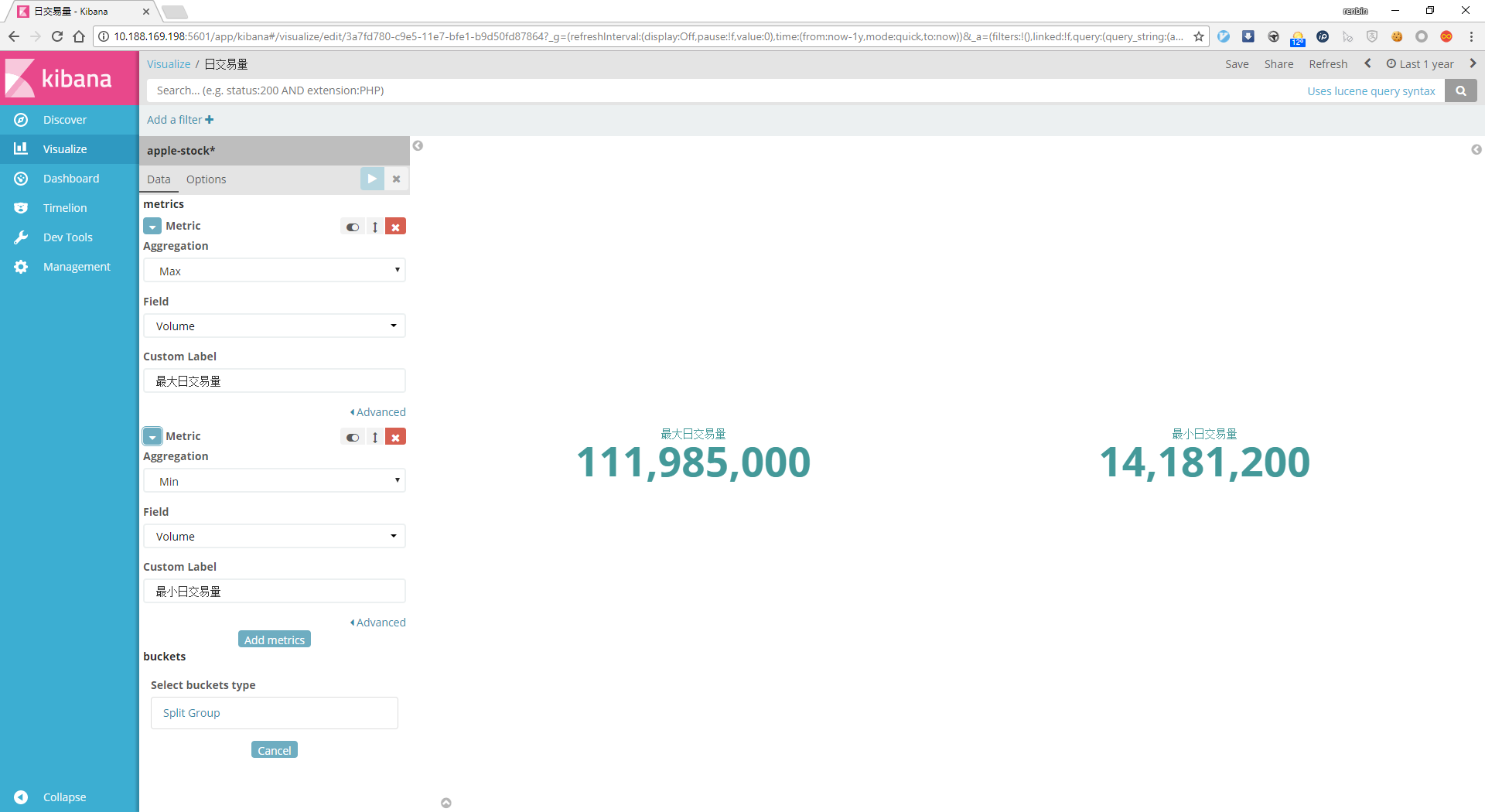
建立数据表格¶
在Visualize菜单选择Data Table数据表格,metric中Aggregation填求和Sum,字段为成交量Volume,buckets中Aggregation选择Date Histogram,间隔interval为每月,填入各自的自定义标签,保存为每月总交易量
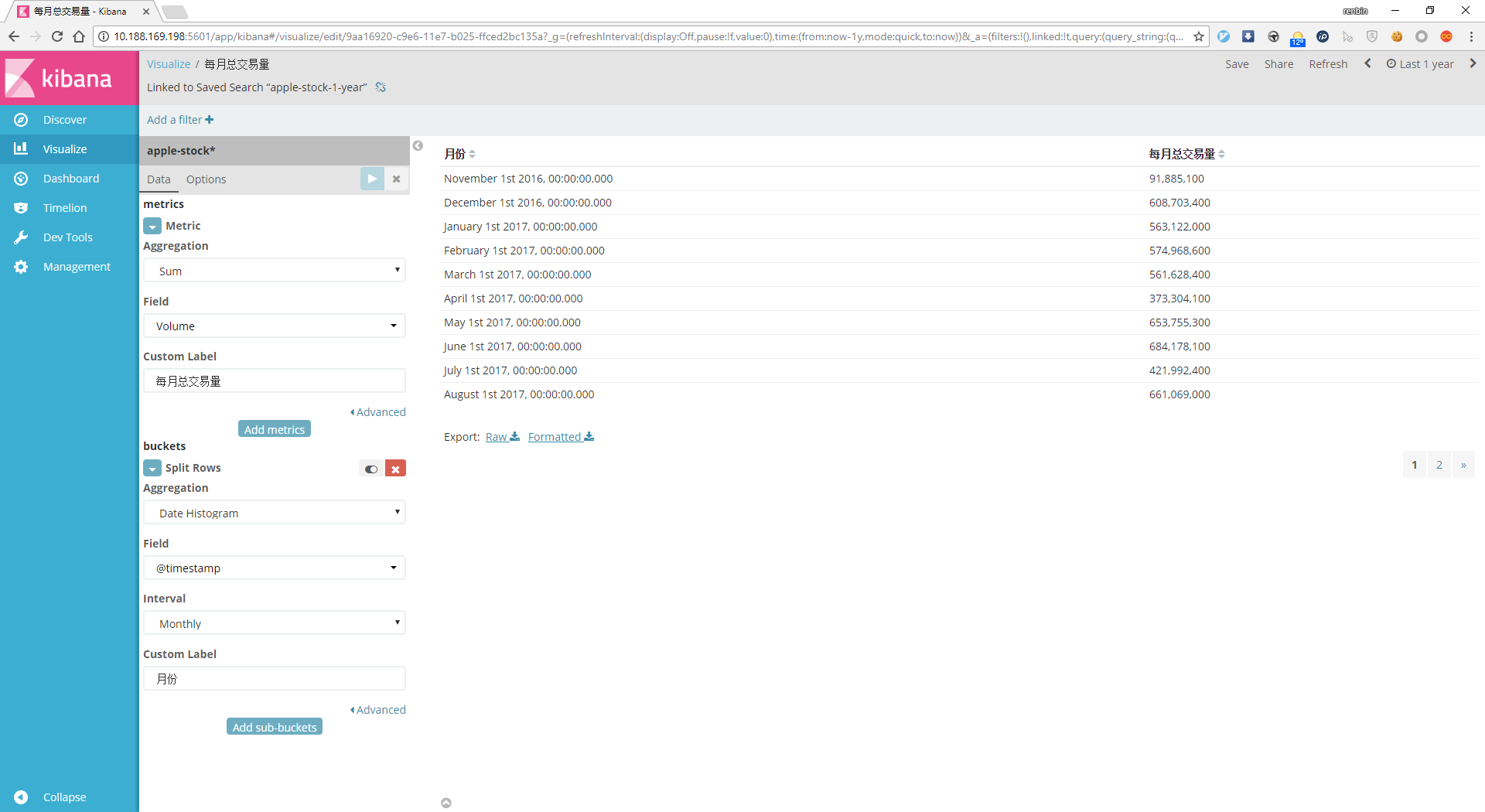
建立Dashboard¶
在kibana页面中选择Dashboard标签,创建1个dashboard名为AAPL股票信息,选择刚刚创建的4个视图,集中展示改股票信息:
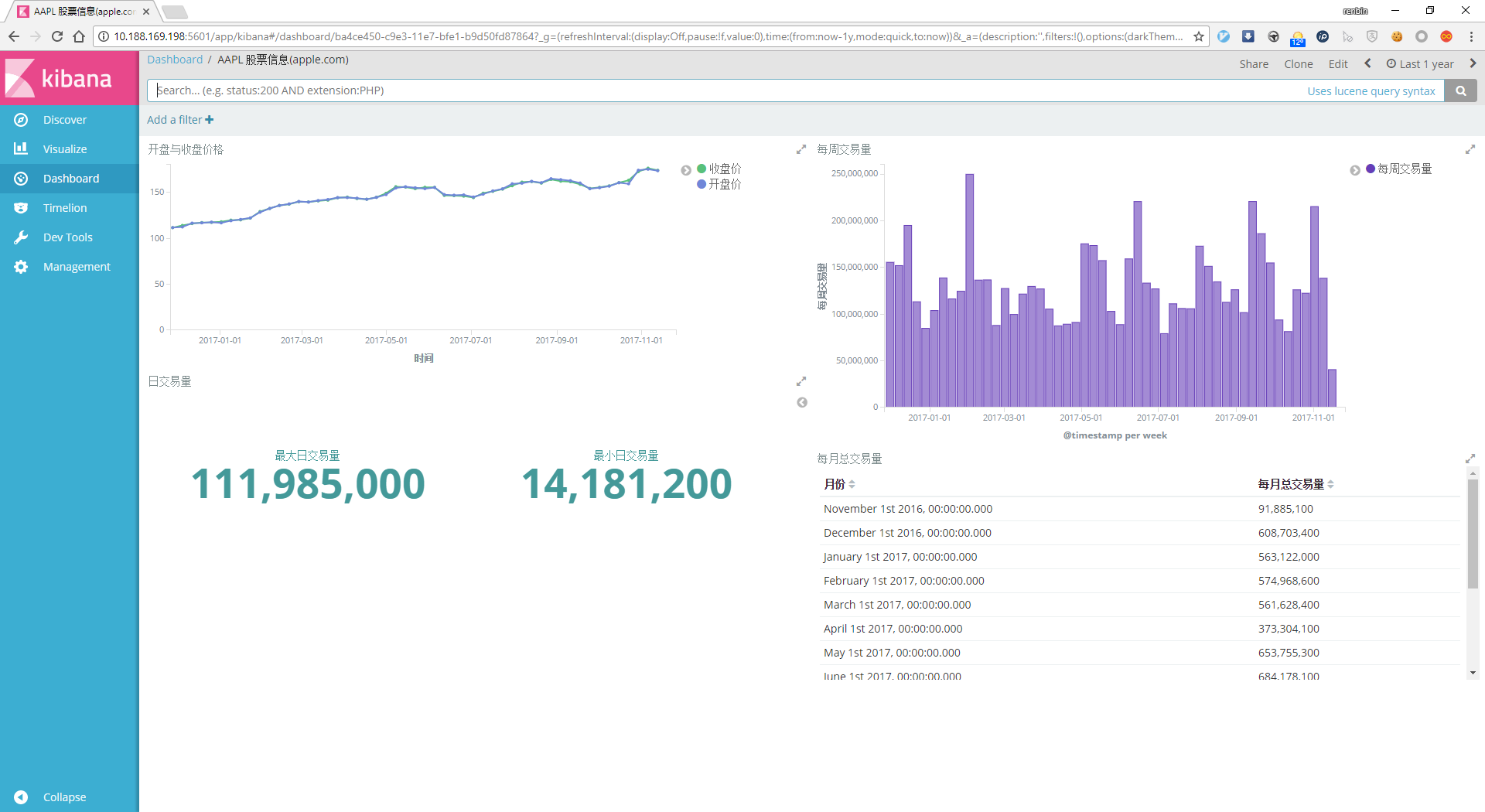
至此,利用logstash输入,过滤,输出到elasticsearch中,创建索引,并用kibana展示该数据管道完成
总结¶
介绍了目前各大分布式环境下的日志系统架构,并对应用广泛、灵活性较强的 ELK 日志系统架构进行了详细分析,分别阐述了不同应用环境下的 ELK 架构的优缺点,并给出了 ELK 日志系统在业务系统中的应用案例。 经过实践,ELK 日志系统作为一个开源的分布式日志系统,能够为用户提供稳定、可靠的准实时搜索服务,并且能够提供多种报表供用户选择,为用户在故障排查、数据分析时提供帮助。